"# <center>Using Topological Data Analysis with Statistical Models</center>\n",
"\n",
"<center>by Shawk Masboob</center>"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Topological data analysis (TDA) and more specifically Mapper, can be used to enhance statistical modeling. Mapper is a useful tool to visualize large datasets because it transforms the data into a graph which can then be further analyzed. Standard statistic methods can often miss or “not see” the complexities that lie within data. Hence, using Mapper can greater improve statistical modeling such as classification, prediction, or forecasting. \n",
"\t\n",
"This project incorporates statistical modeling with TDA to demonstrate how Mapper works. The project used the California Housing dataset.The project begins by using standard statistical methods for exploratory data analysis and getting rid of multicollinearity such as the variance inflation factor. Stepwise regression was used to determine the which features should be used in the model. After determining the necessary features, a multiple linear regression was used to predict house price based on varying attributes such as number of bedrooms and location. \n",
"\n",
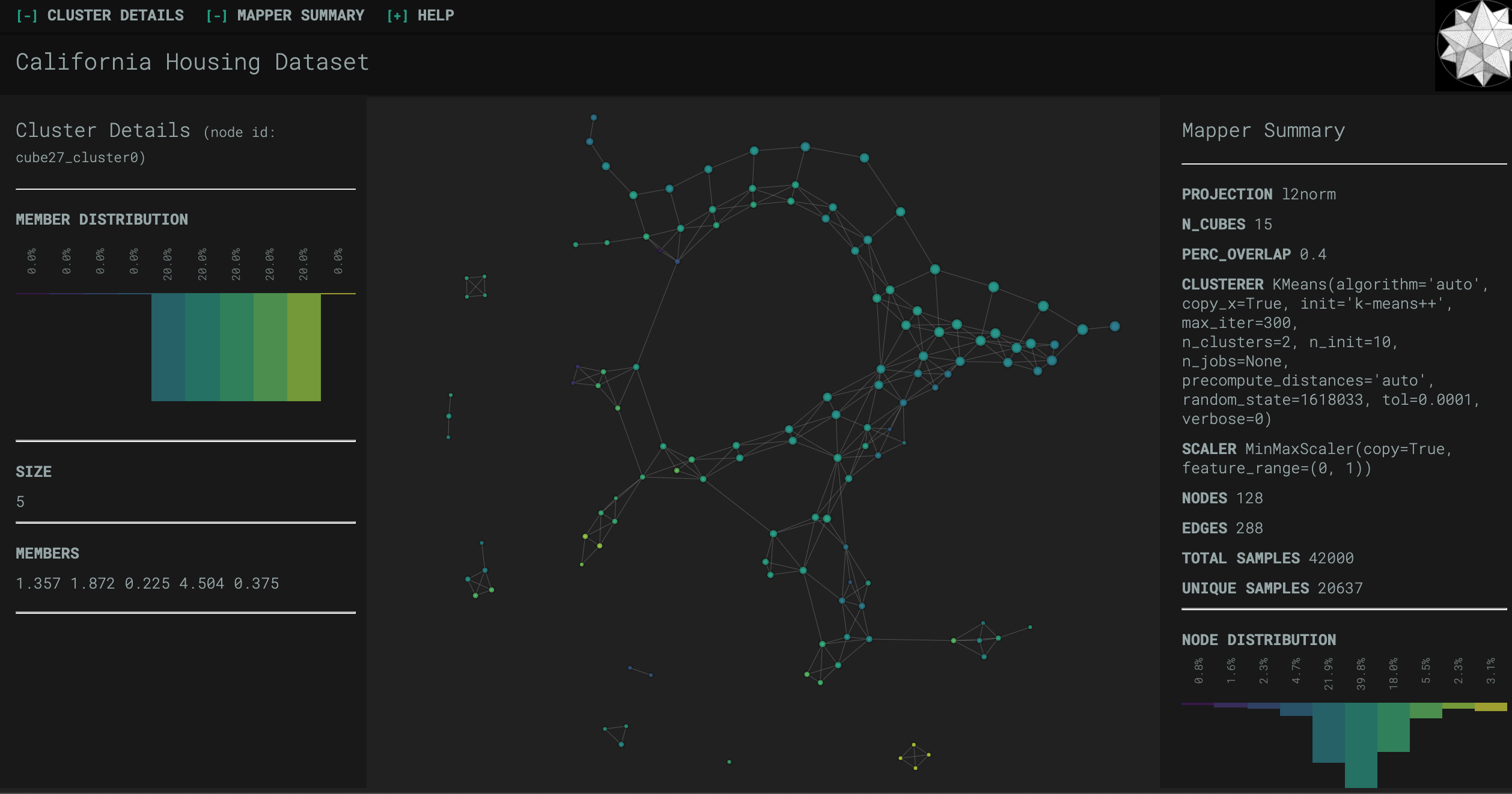
"Mapper was used after building the linear model. While Mapper has multiple purposes, in this project it was used to evaluate the dataset and determine whether certain portions of the dataset behave differently. Mapper allows users to use different lenses, cover, and type of clustering method. The point was to find natural separation within the data. A visualization was created to demonstrate the separated nodes. The figure below shows the mapper output for the California dataset. \n",
"\n",
"\n",
"\n",
"Although the lenses used need to be improved because not enough separation is being shown, one can analyze the nodes individually. The idea is, separation between the nodes implies that the data behaves differently and hence, running a regression on the nodes individually might present interesting results. The next step in this project is to 1.) improve the separation by changing the lenses or clustering method and 2.) running a regression on the each node. The node might have different features, e.g. one node might exclude ‘number of bedrooms’ because it might not contribute to predicting house price. Another node might include ‘number of bedrooms.’ \n",
"\n",
"There are plenty of examples which incorporate TDA in statistical analysis using Mapper. For example, one research examined Wisconsin cancer data. The aim of the research was to classify breast cancer patients. That is, the goal of the research was to determine which of the 11 predictor variables have the most influence on the diagnosis [1]. The researchers began by building a logistic regression model. They concluded that although a logistic model is appropriate for their data and research topic, there was still room for improvement because misdiagnoses still presented to be an issue [1]. After the statistical analysis was completed, the researchers added Mapper to improve the research. TDA was capable of sorting between people with benign tumors and those with malignant tumors. After simply analyzing the nodes, the researchers looked deeper at the nodes to understand what caused the separation [1]. The researches, after using an exhaustive search, found that the nodes do behave different and hence, separate logistic models were created for each node [1]. To conclude, the researchers found that standard statical modeling was prone to false negatives and false positives. Using TDA, the researchers found that “there is a subset of patients that share similarities in many attributes such as mean area and perimeter, but differ wildly in the smoothness of the tumor, and this observation leads to a different model and consequently a different diagnosis” [1].\n",
"\n",
"The main idea behind using TDA when building a statistical model (e.g. multiple linear regression) is that data can behave differently and sometimes relying on traditional statistical methods is not enough. That is, standard statistical methods do not always capture the behavior of the data and hence, the developed models do not lead to the best prediction. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"# References\n",
"\n",
"[1] Allen, Dylan. Topological Data Analysis: Giving Data Shape. Carroll, 13 May 2017, scholars.carroll.edu/cgi/viewcontent.cgi?article=1000&context=mathengcompsci_theses."
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3"
}
},
"nbformat": 4,
"nbformat_minor": 1
}
%% Cell type:markdown id: tags:
# <center>Using Topological Data Analysis with Statistical Models</center>
<center>by Shawk Masboob</center>
%% Cell type:markdown id: tags:
Topological data analysis (TDA) and more specifically Mapper, can be used to enhance statistical modeling. Mapper is a useful tool to visualize large datasets because it transforms the data into a graph which can then be further analyzed. Standard statistic methods can often miss or “not see” the complexities that lie within data. Hence, using Mapper can greater improve statistical modeling such as classification, prediction, or forecasting.
This project incorporates statistical modeling with TDA to demonstrate how Mapper works. The project used the California Housing dataset.The project begins by using standard statistical methods for exploratory data analysis and getting rid of multicollinearity such as the variance inflation factor. Stepwise regression was used to determine the which features should be used in the model. After determining the necessary features, a multiple linear regression was used to predict house price based on varying attributes such as number of bedrooms and location.
Mapper was used after building the linear model. While Mapper has multiple purposes, in this project it was used to evaluate the dataset and determine whether certain portions of the dataset behave differently. Mapper allows users to use different lenses, cover, and type of clustering method. The point was to find natural separation within the data. A visualization was created to demonstrate the separated nodes. The figure below shows the mapper output for the California dataset.

Although the lenses used need to be improved because not enough separation is being shown, one can analyze the nodes individually. The idea is, separation between the nodes implies that the data behaves differently and hence, running a regression on the nodes individually might present interesting results. The next step in this project is to 1.) improve the separation by changing the lenses or clustering method and 2.) running a regression on the each node. The node might have different features, e.g. one node might exclude ‘number of bedrooms’ because it might not contribute to predicting house price. Another node might include ‘number of bedrooms.’
There are plenty of examples which incorporate TDA in statistical analysis using Mapper. For example, one research examined Wisconsin cancer data. The aim of the research was to classify breast cancer patients. That is, the goal of the research was to determine which of the 11 predictor variables have the most influence on the diagnosis [1]. The researchers began by building a logistic regression model. They concluded that although a logistic model is appropriate for their data and research topic, there was still room for improvement because misdiagnoses still presented to be an issue [1]. After the statistical analysis was completed, the researchers added Mapper to improve the research. TDA was capable of sorting between people with benign tumors and those with malignant tumors. After simply analyzing the nodes, the researchers looked deeper at the nodes to understand what caused the separation [1]. The researches, after using an exhaustive search, found that the nodes do behave different and hence, separate logistic models were created for each node [1]. To conclude, the researchers found that standard statical modeling was prone to false negatives and false positives. Using TDA, the researchers found that “there is a subset of patients that share similarities in many attributes such as mean area and perimeter, but differ wildly in the smoothness of the tumor, and this observation leads to a different model and consequently a different diagnosis” [1].
The main idea behind using TDA when building a statistical model (e.g. multiple linear regression) is that data can behave differently and sometimes relying on traditional statistical methods is not enough. That is, standard statistical methods do not always capture the behavior of the data and hence, the developed models do not lead to the best prediction.
%% Cell type:markdown id: tags:
---
# References
[1] Allen, Dylan. Topological Data Analysis: Giving Data Shape. Carroll, 13 May 2017, scholars.carroll.edu/cgi/viewcontent.cgi?article=1000&context=mathengcompsci_theses.

{kind=link}